Gluon is an exciting new Kubernetes controller that brings the full power of BOSH to a Kubernetes world. With three simple and straightforward CRDs, Gluon lets Kubernetes operators deploy VMs via BOSH, upload stemcells, and manage cloud and runtime configs, all from the comfort of kubectl.
Today we’re going to do the improbable: starting with a stock Kubernetes cluster running the Gluon controller, we’re going to apply a single YAML file and deploy another Kubernetes cluster on top of VMs.
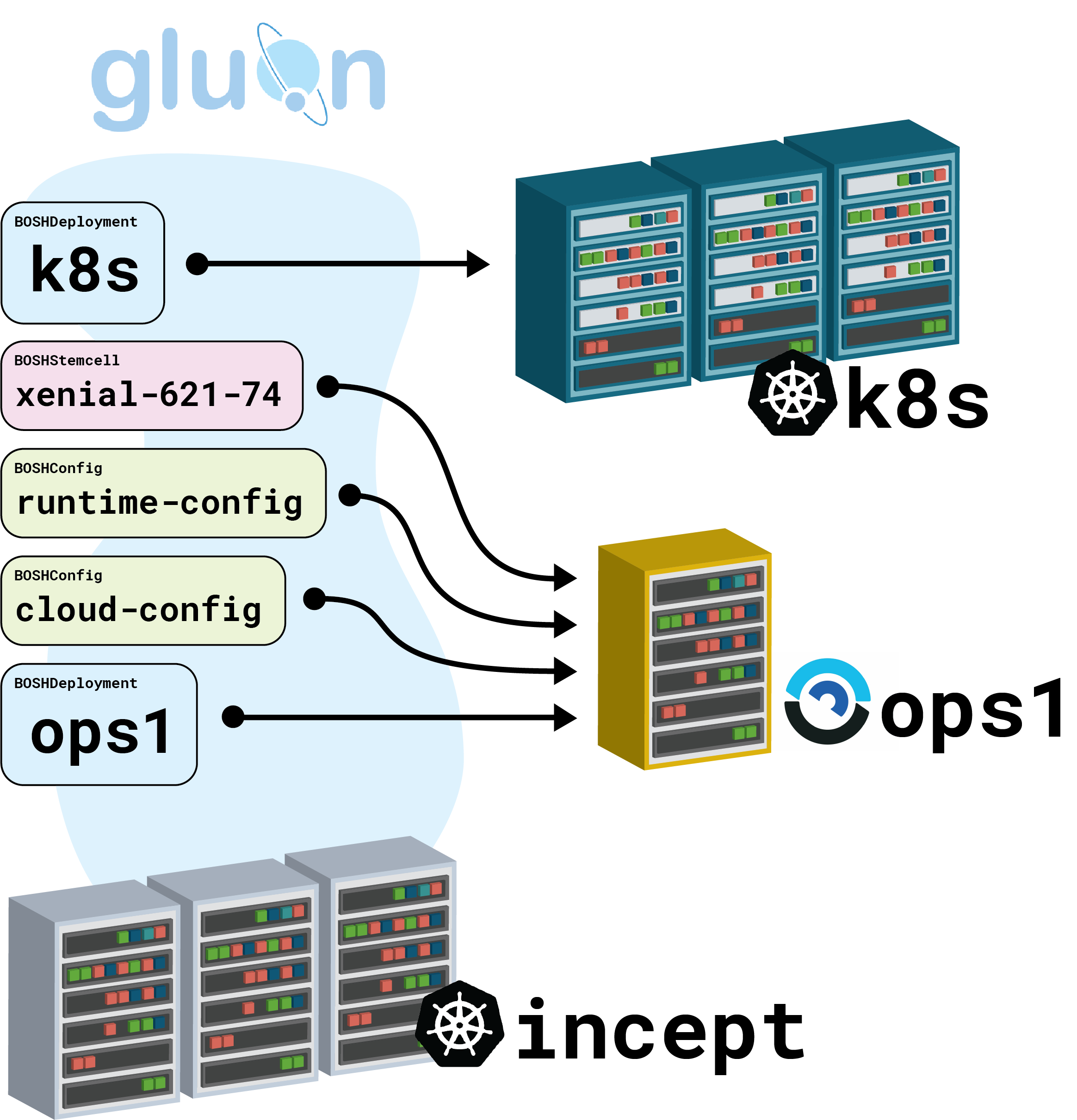
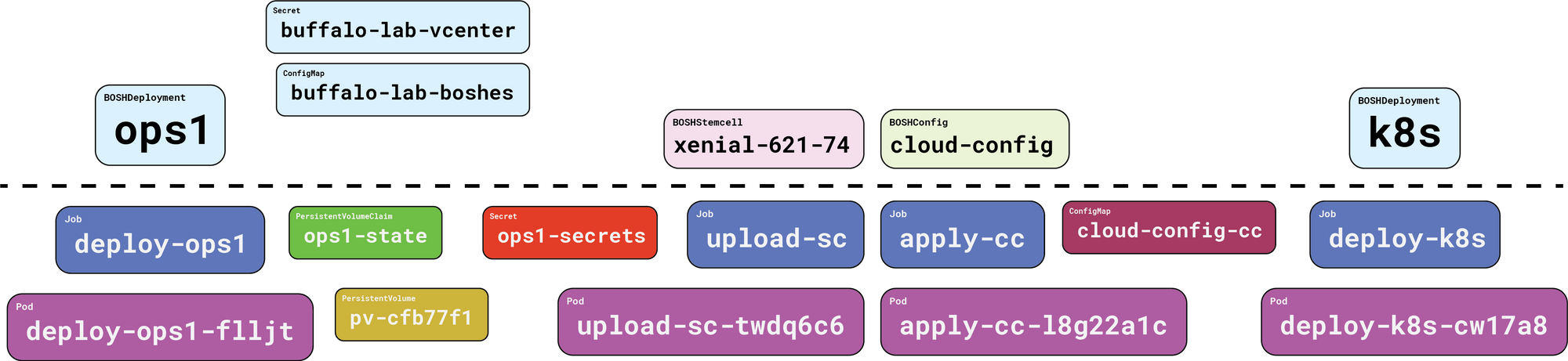
When we’re all done, this is what we’ll have:
First Things First: BOSHDeployment
We start with a BOSHDeployment, which is how we get our ops1 BOSH director up and running:
---
apiVersion: gluon.starkandwayne.com/v1alpha1
kind: BOSHDeployment
metadata:
name: ops1
spec:
repo: https://github.com/cloudfoundry/bosh-deployment
ops:
- uaa
- credhub
- vsphere/cpi
vars:
- configMap: { name: bosh-settings }
- secret: { name: vsphere-creds }
- name: internal_ip
value: 10.0.0.4Note: I’m using vSphere here; you will want to substitute the CPI ops files and variables that you need for your favorite IaaS.
The majority of the configuration for vSphere exists in the buffalo-lab-boshes Kubernetes ConfigMap. It looks like this:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: buffalo-lab-boshes
data:
vcenter_ip: your.vsphere.example.com
vcenter_dc: dc1
vcenter_cluster: cluster1
vcenter_ds: store1
internal_cidr: 10.0.0.0/8
internal_gw: 10.0.0.1
network_name: VM Network
vcenter_disks: gluon/demo/disks
vcenter_templates: gluon/demo/templates
vcenter_vms: gluon/demo/vmsThe credentials, which in BOSH-land are called vcenter_username and vcenter_password, are safely tucked away in a Kubernetes Secret named buffalo-lab-vcenter – no, I won’t show you that one. The important point is that the combination of the shared ConfigMap, the private Secret, and the literal specification of internal_ip by name and value make up all of the variables I’m going to use to deploy my director.
This enables substantial variable re-use. If we specify multiple ConfigMaps, values present in later ones will override the values present in earlier ones, similar in spirit to BOSH ops file patching.
Operating System: BOSHStemcell
Next up is BOSHStemcell, which handles the task of uploading stemcells to a BOSH director so that it can deploy other VMs using those images. Here’s an Ubuntu Xenial stemcell, in Kubernetes terminology:
---
apiVersion: gluon.starkandwayne.com/v1alpha1
kind: BOSHStemcell
metadata:
name: xenial-621-74
spec:
director: ops1
name: bosh-vsphere-esxi-ubuntu-xenial-go_agent
version: '621.74'
url: https://bosh-core-stemcells.s3-accelerate.amazonaws.com/621.74/bosh-stemcell-621.74-vsphere-esxi-ubuntu-xenial-go_agent.tgz
sha1: 0d927b9c5f79b369e646f5c835e33496bf7356c5Configuration: BOSHConfig
Finally, we have BOSHConfig, which takes care of applying both Cloud Configs and Runtime Configs to a BOSH director, so that it can find things like networks, and size VMs appropriately. Because these two types are so close in both purpose and format, Gluon treats them as variations on a single Custom Resource Type.
Here’s a Cloud Config (edited for brevity – see this gist for the full file):
---
apiVersion: gluon.starkandwayne.com/v1alpha1
kind: BOSHConfig
metadata:
name: cloud-config
spec:
director: ops1
type: cloud
config: |
azs:
- name: z1
cloud_properties: ...
vm_types:
- name: default
cloud_properties: ...
disk_types: ...
compilation: ...
# etc...The spec.type field marks this as a “cloud” config, and spec.director tells us it will be applied to the ops1 director we configured above.
Runtime Configs look very similar:
---
apiVersion: gluon.starkandwayne.com/v1alpha1
kind: BOSHConfig
metadata:
name: runtime-config
spec:
director: ops1
type: runtime
config: |
addons:
- name: bosh-dns
jobs:
- name: bosh-dns
release: bosh-dns
releases:
- name: bosh-dns
version: 1.21.0
sha1: ...
url: ...
# etc.Deploying Kubernetes via VMs… via Kubernetes
Here’s where things start to get meta.
We’re going to use our ops1 BOSH director to deploy another Kubernetes cluster, on VMs, using the k8s BOSH Release.
---
apiVersion: gluon.starkandwayne.com/v1alpha1
kind: BOSHDeployment
metadata:
name: k8s
dependencies:
dependsOn:
- stemcell: xenial-621-74
- config: cloud-config
- config: runtime-config
spec:
director: ops1
repo: https://github.com/jhunt/k8s-deployment
entrypoint: k8s.ymlThe k8s-deployment repository we’re using here works out-of-the-box, with no additional BOSH ops files or variables necessary. All we need to do is hook up our BOSHDeployment resource to the repository, put in our (explicit) dependencies on the stemcell, cloud-config, and runtime-config, and let Gluon do the rest.
Kubernetes and The Declarative Way
Chances are that if you are deploying BOSH things today via the bosh CLI, you’re accustomed to a decidedly imperative workflow. First we create the director. Then we upload the stemcell. Then apply the runtime config. Then the cloud config. Then deploy more stuff.
Kubernetes doesn’t work that way. With Kubernetes, you tell the cluster what end state you want, and the controllers that comprise the machinery of Kubernetes figure out the steps to go through to get there.
When you want to run a container image, you don’t tell Kubernetes to create a container and pull an image from DockerHub. Instead, you describe the Pod (usually via a Deployment, StatefulSet, or DaemonSet), define what image should be used, how the environment is put together, etc., and the cluster reconciles accordingly.
The fantastic thing about building around this declarative / reconciliation approach is that entire classes of failures that plague imperative systems go away. Ever notice that you can take a running deployment made up of multiple replicas and delete just one Pod to get a fresh replacement? Try doing that in an imperative system!
BOSH is still primarily imperative (resurrection and cloud-check notwithstanding), so Gluon has to figure out how to square that with the declarative nature of BOSHDeployment, BOSHStemcell, and BOSHConfig resources, which brings us to …
Dependencies – Explicit and Implied
The simplest way to translate declarative stuff into imperative steps is via dependency graphs. Consider the deployment we’ve built up so far. Before we can upload the Xenial 621.74 stemcell to the ops1 director, the director itself has to deployed. This is an implicit dependency. Both BOSHConfig resources have similar implicit dependencies.
The k8s BOSHDeployment has an implicit dependency on the ops1 BOSH director, and three explicit dependencies. We spelled them out right there in the metadata:
dependencies:
dependsOn:
- stemcell: xenial-621-74
- config: cloud-config
- config: runtime-configThese have to be explicit, because Gluon cannot deduce from the information available to it (ops files, deployment repository configuration, and variables) which stemcells need to be in place for a successful deployment. It also has no way of knowing if a cloud-config is necessary, nor when the correct VM types, extensions, disk types, and networks are defined. We have to bring some of that with our domain knowledge, and we do that with explicit dependencies.
Under the Hood – Using Jobs & Pods
The terrifically subversive part of Gluon is that it doesn’t provide much in the way of actual new functionality so much as it repackages functionality we already have with Kubernetes: Jobs and Pods.
Take a BOSHDeployment for instance. When you create one of these objects via kubectl apply -f ..., the Gluon controller turns it into a Job object and lets the core bits of Kubernetes handle it from there. Gluon worries about what it means to do BOSH things, while Kubernetes concerns itself with the minutiae of retrieving Docker images constructing container groups, setting environment variables, mounting secrets, and executing processes.
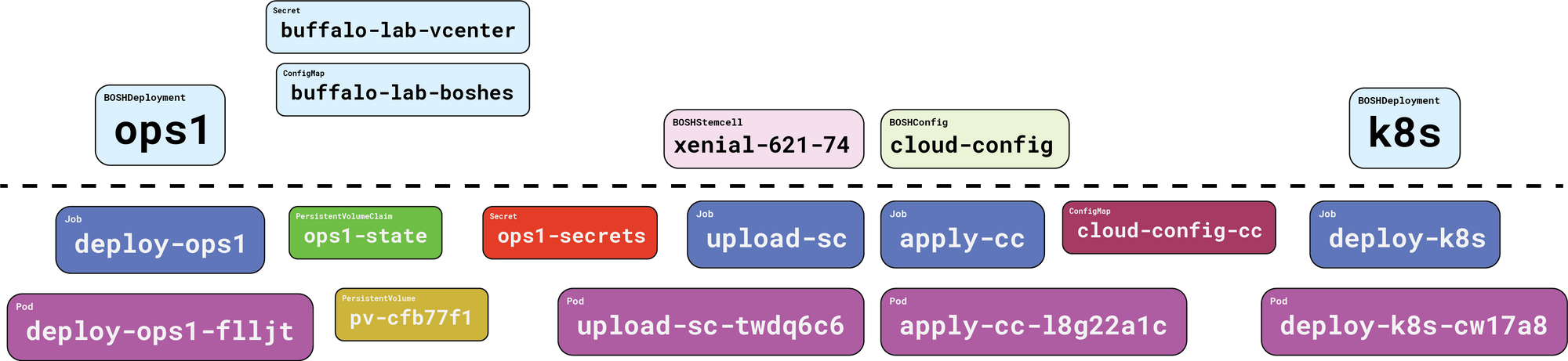
Here’s what we ended up with when we created our ops1 BOSHDeployment:
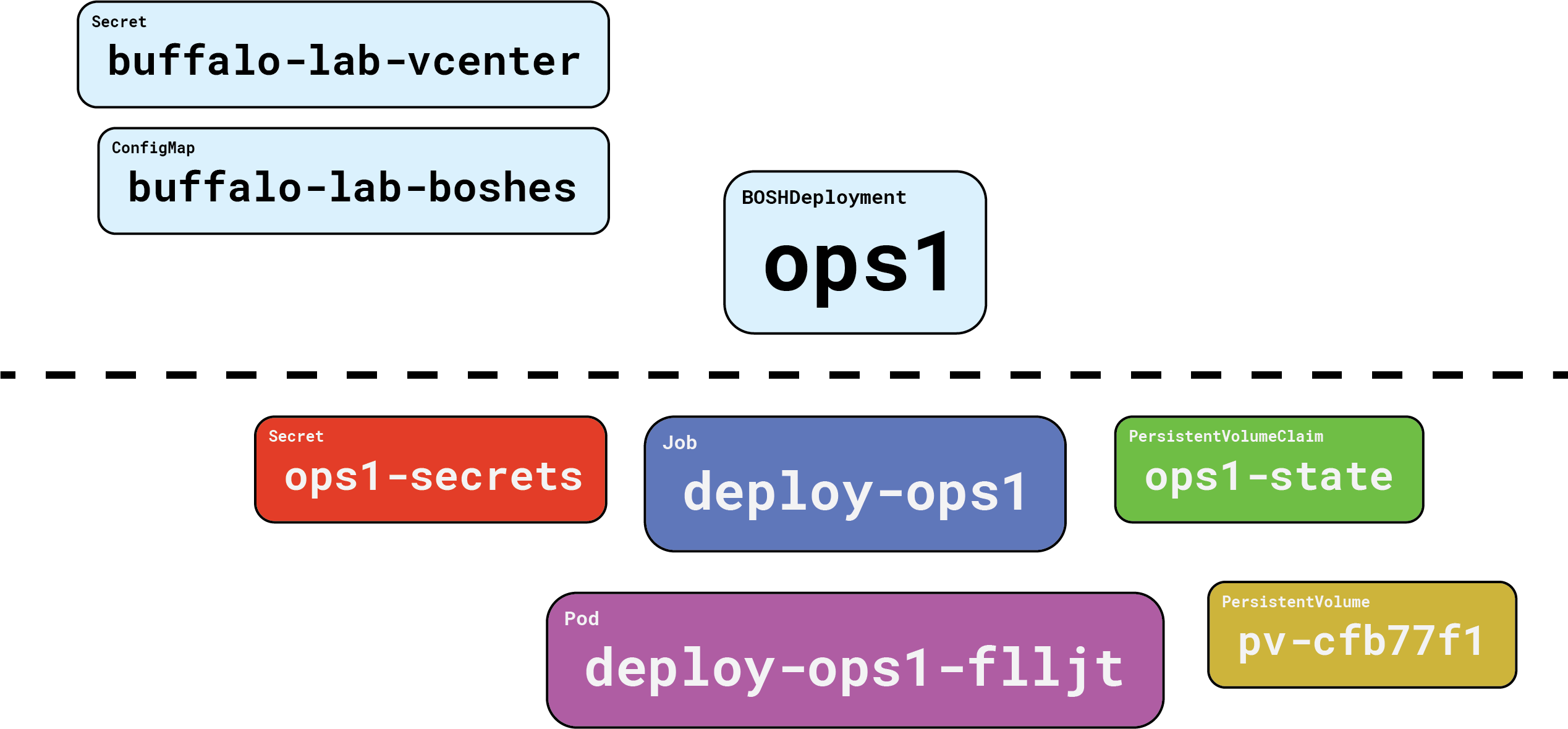
Everything above the dotted line is our responsibility. Everything below the dotted line is handled on our behalf, by Gluon.
First, and perhaps most importantly, we get a PersistentVolumeClaim, and its associated PersistentVolume. This is where Gluon will cache compiled packages. More importantly, the BOSH state file will be kept here. This state file tracks the names of our director VM and its persistent disk, which makes it incredibly important. Without a state file, you cannot update, reconfigure, or recover a lost director.
And Gluon handles that for you! Nice.
Next up we get a Job, which in turn creates a Pod that pulls down the starkandwayne/gluon-apparatus OCI image from DockerHub, and executes it to run the actual bosh create-env command, with all the right flags, in the right order. When it’s all done, the apparatus image reaches back into Kubernetes and creates a Secret which stores the four things we need to connect to our new BOSH director and use it: the endpoint URL, the admin credentials (username + password), and the certificate authority that signed the TLS server certificates.
Once all that is taken care of, Gluon will consider the BOSHDeployment for ops1 to be “ready”, and will move onto things that depended on it. Next up is our stemcell.

As before, everything above the dotted line is our responsibility; Gluon handles everything below. To get our stemcell into our BOSH director, Gluon fashions a Job, with references to the BOSH credentials via the ops1-secrets Secret. This Job in turn causes a Pod to spring into existence (thanks, Kubernetes!) which then runs some more Gluon OCI image bits to execute the bosh upload-stemcell command.
In parallel, Gluon is also reconciling our BOSHConfig objects, since the director is ready and there are no other dependencies. Here’s what that looks like:
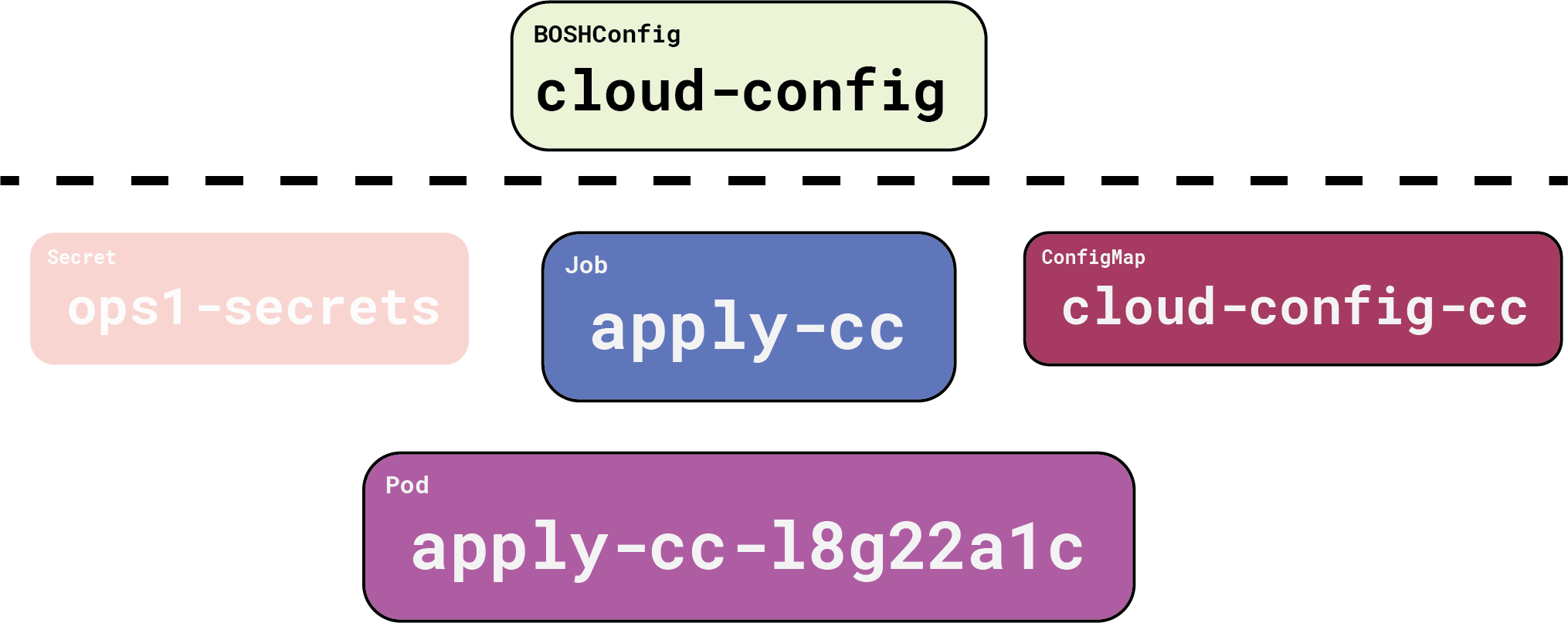
Again, everything above the dotted line is what we are responsible for and Gluon handles the rest. Gluon turns a ready BOSHConfig into a Job object referencing the BOSH credentials (ops-secrets), and a ConfigMap containing the requested configuration YAML. The ConfigMap is mostly hidden; when we change our BOSHConfig, Gluon transparently overwrites the ConfigMap to make things work.
So There You Have It
With that little bit of YAML (~200 lines!), and the Gluon controller, we now have a BOSH director and a 3-node Kubernetes cluster. Voilà!
More Gluon!
Intrigued? Want to learn more?
You’re in luck. We have a video introduction to Gluon, over on YouTube, in which I build out a Cloud Foundry in much the same way. I’m told the “live” demo part is absolutely fantastic. 🎶
The full YAML file (minus the sensitive credentials) is available in this gist, if you wanted to review the nuts-and-bolts of this exercise.
If you want to dig into the code, it’s hosted on GitHub. We’re tracking issues for known problems and future roadmap direction. If you get stuck trying to run the controller locally, or in your cluster, reach out to us on Twitter, @iamjameshunt or @starkandwayne, using the hashtag #AllGluedUp, or just file an issue against the GitHub project.

Spread the word